Book Review: Crossing the Chasm
I don’t remember how Crossing the Chasm got onto my reading list (maybe the Fog Creek Software Management Training Program Reading List?) but I finally got around to reading it over the last couple weeks. One sentence review: It’s a great book for developers and product managers working at small software shops / start ups that want to to take their business to the next level. And now for a bunch of poignant excerpts…
The book hinges on the idea that a giant chasm exists in between the early adapters and the early majority (hence the title), as evidenced by this bell curve:
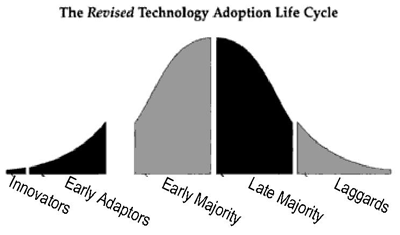
For posterity’s sake, the author defines the early adopter as someone who wants to buy a change agent, something that will
“… get [them] a jump on the competition, whether from lower product costs, faster time to market, more complete customer service, or some other comparable business advantage.”
In comparison, the early majority
“… want to buy a productivity improvement for existing operations. They are looking to minimize the discontinuity with the old ways. They want evolution, not revolution. They want technology to enhance, not overthrow, the established ways of doing business.”
(pg 20)
What is marketing?
… taking actions to create, grow, maintain, or defend markets… Marketing’s purpose, therefore, is to develop and shape something that is real, and not, as people sometimes want to believe, to create illusions. In other words, we are dealing with a discipline more akin to gardening or sculpting than, say, to spray painting or hypnotism… a market is
- a set of actual or potential customers
- for a given set of products or services
- who have a common set of needs or wants, and
- who reference each other when making a buying decision
(pg 28)
You need to read the book to understand why the following excerpt is important, but I think this paragraph sums up a lot of what the book is about:
Companies just starting out, as well as any marketing program operating with scarce resources must operate in a tightly bound market to be competitive. Otherwise, their “hot” marketing messages get diffused too early, the chain reaction of word-of-mouth communication dies out, and the sales force is back to selling “cold.” This is classic chasm symptom, as the enterprise leaves behind the niche represented by the early market. It is usually interpreted as a letdown in the sales force or a cooling off in the demand when, in fact, it is simply the consequence of trying to expand into too loosely bound a market. The D-Day strategy prevents this mistake. It has the ability to galvanize an entire enterprise by focusing it on a highly specific goal that is 1) readily achievable and 2) capable of being directly leveraged into a long term success. Most companies fail to cross the chasm because, confronted with the immensity of the opportunity represented by a mainstream market, they lose their focus, chasing every opportunity that presents itself, but finding themselves unable to deliver a salable proposition to any true pragmatist buyer. The D-Day strategy keeps everyone on point — if we’d don’t take Normandy, we don’t have to worry about how we’re going to take Paris. And by focusing our entire might on such a small territory, we greatly increase our odds of immediate success.
(pg 67)
On product-centric / pre-chasm companies compared to market-centric / post-chasm companies:
… we must shift our marketing focus from celebrating product-centric value attributes to market-centric ones. Here is a representative list of each:
Product Centric
- Fastest product
- Easiest to use
- Elegant Architecture
- Product Price
- Unique Functionality
Market-Centric
- Largest installed base
- Most third party supporters
- De facto standard
- Cost of ownership
- Quality of support
(pg 137)
I’m leaving out a number of other excerpts that I dog eared because it’s late but the excerpts probably won’t do you any good any way, read it and then these might jog your memory.
{kind=link}