Catching up on links… Matt Quail wrote about Lucene and it’s use of an inverted index a couple months ago and then today John Battelle linked to ‘backrub‘ (google before google existed) which also mentions the use of an inverted index.
Category Archives: Software Development
UBL 1.0
Last week Tim Bray mentioned the May 1st release of UBL 1.0, which he defines as “… a set of general-purpose XML-encoded business documents: orders, acknowledgments, packing slips, invoices, receipts.” He goes on to compare UBL to HTML, saying that because it (UBL) is a generic format rather than a format made for a particular industry (just like HTML was a generic, simpler subset of SGML), it has a chance to become the HTML of the business document world (read: explosive growth, eventual ubitquity). Tim quotes an email from Jon Bosak on some of the other reasons for the creation of UBL:
· Developing and maintaining multiple versions of common business documents like purchase orders and invoices is a major duplication of effort.
· Creating and maintaining multiple adapters to enable trading relationships across domain boundaries is an even greater effort.
· The existence of multiple XML formats makes it much harder to integrate XML business messages with back-office systems.
· The need to support an arbitrary number of XML formats makes tools more expensive and trained workers harder to find.
My current project, which should be released soon, utilizes software from many different companies: tax software, credit card software, shipping rate software, custom software written by the company that manages the distribution of product, etc.. Obviously having a single format to work with would decrease the time I spend a) digging through each companies documentation trying to understand their format and b) wiring up the custom documents for each format, so I’m definitely looking forward to the day when I can use UBL.
For anyone interested, it looks like there is a smattering of support for UBL out there in the Java world: http://softml.net/jedi/ubl/sw/java/, https://jwsdp.dev.java.net/ubl/, http://www.sys-con.com/story/?storyid=37553&DE=1. For further information regarding UBL, see the OASIS UBL TC web page at:
http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=ubl
Hibernate: Non object retrieval
Hibernate has significantly reduced the amount of time I’ve spent on the writing and maintaining SQL in the applications I’m working on. Because it exists to map data from Java classes to database tables and back, there aren’t alot of examples on the site if you need to get non object data out of the database (for instance if you’re doing reporting on the existing data). That’s not to say that it’s not possible! Given a Query object, call the list() method and then iterate over the resulting List. Calling the get() method on the list results in an array of Objects (which is analogous to a row returned from a resultset). Then you’ll just need to retrieve the appropriate element of the array given your SQL query (where the order of the items in your ‘SELECT ..’ SQL query determines the order in which the objects are returned in the Object[]).
// .. code to create a Query object
List list = q.list();
for (int i=0; i
If you're having trouble finding out the Java type of the element in a row, I've found Hibern8IDE to be an excellent help in running, testing and debugging Hibernate queries.
Struts & Java Tips: Issue #2
A couple weeks ago I wrote a short essay on some of the things that I ran into while working with Java and Jakarta Struts. Because I didn’t know what else to call it, I jokingly referred to it as Issue #1. Well, a month and a half later I think I have enough to write issue #2. I should probably call it something more general like ‘Java Web Development Tips’ or something, but why change now?
First, I thought I’d touch on some of the interesting things that I’ve run into while working in the presentation layer which in my case is JSP. This week I needed to create a search form that enabled end users to sort and filter results based on a number of parameters. Without showing 1000 lines of code, one of the challenges when doing a form like this is maintaining the form state when doing filtering and sorting (because not all the fields are sortable and not all can be filtered) and the most common solution is to use hidden form fields. Struts includes a <html:hidden> tag that will automatically maintain state for you form, but it requires that you know all the names of all the fields up front when you’re writing your form. If you decide to add a sortable or filterable property later, you’d need to hardcode another hidden form field. Instead, I chose to use the JSTL forEach tag and the special ‘param’ scope to programatically create my hidden form fields:
<c:forEach var="p" items="${param}">
<input type="hidden" name="${p.key}" value="${p.value}">
</c:forEach>
The non-intuitive part of this code in my mind is the param ‘scope’, which (if you mess around with it a bit) is a HashMap derived from the getParameterMap() method of the ServletRequest interface. The forEach tag iterates over each parameter, which results in a Map.Entry; the Map.Entry provides JavaBean style accessors for key and value, which I can then use to create the hidden form fields.
The Action class that backs the search form uses an ActionForm to collect the data and then copies the data from the ActionForm bean to a bean made specifically for use with the search DAO. That code looks something like this:
public ActionForward execute(ActionMapping m, ActionForm f, HttpServletRequest req, HttpServletResponse res)
throws Exception {
...
// get the data posted from the form
SearchOrdersForm input = (SearchOrdersForm)f;
// bean coupled w/ the search DAO
ManagerSearchParams sp = new ManagerSearchParams();
// copy the properties from the form to the searchparams bean
// using the BeanUtils class
BeanUtils.copyProperties(sp, input);
// perform the search (in this case we're looking for orders
Collection orders = OrderDAO.findOrders(sp);
// push the collection to the jsp
request.setAttribute("orders", orders);
I’m not sure if there is a pattern in this or not, but the coupling of the ManagerSearchParams bean with the OrderDAO in the above example turned out (at least so far) to be very useful. Another part of the application required that I retrieve orders from persistent storage (in this case Hibernate & SQL Server) by date (ie: I needed to find all orders between date1 and date2). Instead of writing a new method on the DAO (ie: OrderDAO.searchbyDate()), the ManagerSearchParams bean already had start & end date properties. I simply created a new instance of the ManagerSearchParams bean, populated the startdate and enddate properties, and then fired the findOrders() method on the OrderDAO class.
a9.com
Amazon launched a new search engine today… a9.com, more from John Battelle.
Wanted: Extracting summary from HTML text
As part of a project I’m working on I need to extract content from an HTML page, in some sense creating a short 200 character summary of the document. Google does a fantastic job of extracting text and presenting a summary of the document in their search listings, I’m wondering how they do that. Here’s the process I’m using right now:
a) Remove all of the HTML comments from the page (ie: <!– –>) because JavaScript is sometimes inside comments, which sometimes includes > and or < which causes (d) to fail
b) Remove everything above the <body> tag, because there isn’t anything valuable there anyway.
c) Remove all the <a href… > tags, because text links are usually navigation and are repeated across a site… they’re noise and I don’t want them. However, sometimes links are part of the summary of a document… removing a link in the first paragraph of a document can render the paragraph unreadable, or at least incomplete.
b) Remove all the HTML tags, the line breaks, the tabs, etc.. using a regular expression.
For the most part, the above 4 steps do the job, but in some cases not. I’ll go out on a ledge and say that most HTML documents contain text that is repeated throughout the site again and again (header text like Login Now! or footer text like copyright 2004, etc…). My problem is that I want to somehow locate the snippets that are repeated and not include them in the summaries I create… For example, on google do this search and then check out the second result:
Fenway Park. … Fenway Park opened on April 20, 1912, the same day as Detroit’s Tiger Stadium and before any of the other existing big league parks. …
That text is way about 1/4 of the way down in the document. How do they extract that?
Parameters: a) I don’t know anything about the documents that I’m analyzing, they could be valid XHTML or garbled HTML from 1996, b) it doesn’t have to be extremely fast, c) I’m using Java (if that matters) , d) I’ve tried using the org.apache.lucene.demo.html.HTMLParser class, which has a method getSummary(), but it doesn’t work for me (nothing is ever returned)
Any and all ideas would be appreciated!
PGP Encryption using Bouncy Castle
It can’t be that hard. So given a couple hours of hacking with the library, here’s a fully illustrated example that shows how to encrypt a file using the Bouncy Castle Cryptography API and PGP. First, giving credit where credit is due, the example comes mostly from the KeyBasedFileProcessor example that ships with the Bouncy Castle PGP libraries. You can find it in the /src/org/bouncycastle/openpgp/examples directory if you download the source. I’ve simply unpacked the example a little, providing some pretty pictures and explanation of what the various pieces are.
As in any example, you need to have downloaded a couple libraries; in this case you need to visit http://www.bouncycastle.org/latest_releases.html and download the bcprov-jdk14-122 and bcpg-jdk14-122 jar files. Add those to your project, as in this example, simply make sure to add them to the classpath when running the example from the command line.
Next, while you don’t need to have PGP installed, you do need to have a at least one public keyring file available on your system. I’m using PGP 6.5.8 on Windows which automatically saves my public keyring for me. You can find the location of the keyring file by Edit –> Options –> Files from within the PGP Keys window. You should see something like this:
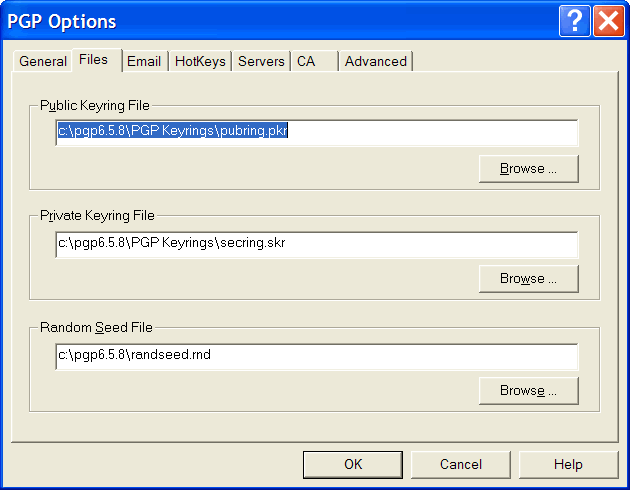
Note the location of the Public Keyring File.
Second, you’ll need to generate a keypair (if you don’t already have one). I won’t go into the how or why (I assume you know the how and why) but you do need to make sure that you create what the Bouncy Castle folks call a ‘RSA key’ or ‘El Gamal key’ (source) rather than a DSA key. If you try to use a DSA keypair (which I’m assuming is synonomous with Diffie-Hellman/DSS?), that I ran into:
org.bouncycastle.openpgp.PGPException: Can't use DSA for encryption, which again is explained by the link above.
Now that you downloaded the appropriate libraries, created an RSA keypair and located your public keyring file, we’re ready to start. Open up your favorite Java IDE (I’m using Eclipse) and start by importing the appropriate libraries:
import java.io.*;
import java.security.*;
import org.bouncycastle.bcpg.*;
import org.bouncycastle.jce.provider.*;
import org.bouncycastle.openpgp.*;
I took a shortcut above and didn’t specify exactly what classes I wanted to import for clarity, if you’re using Eclipse you can easily clean that up by selecting Source –> Organize Imports (or by downloading the source code at the end of this example). Next the class declaration and the standard public static void main etc.. The KeyBasedFileProcessor example on the BouncyCastle website lets you pass in the location of the public keyring and the file you want to encrypt, I’m hardcoding it in my code so that it’s crystal clear what everything is:
// the keyring that holds the public key we're encrypting with
String publicKeyFilePath = "C:\\pgp6.5.8\\pubring.pkr";
and then use the static addProvider() method of the java.security.Security class:
Security.addProvider(new BouncyCastleProvider());
Next I chose to create a temporary file to hold the message that I want to encrypt:
File outputfile = File.createTempFile("pgp", null);
FileWriter writer = new FileWriter(outputfile);
writer.write("the message I want to encrypt".toCharArray());
writer.close();
Read the public keyring file into a FileInputStream and then call the readPublicKey() method that was provided for us by the KeyBasedFileProcessor:
FileInputStream in = new FileInputStream(publicKeyFilePath);
PGPPublicKey key = readPublicKey(in);
At this point it’s important to note that the PGPPublicKeyRing class (at least in the version I was using) appears to have a bug where it only recognizes the first key in the keyring. If you use the getUserIds() method of the object returned you’ll only see one key:
for (java.util.Iterator iterator = key.getUserIDs(); iterator.hasNext();) {
System.out.println((String)iterator.next());
}
This could cause you problems if you have multiple keys in your keyring and if the first key is not an RSA or El Gamal key.
Finally, create an armored ASCII text file and call the encryptFile() method (again provided us by the KeyBasedFileProcessor example:
FileOutputStream out = new FileOutputStream(outputfile.getAbsolutePath() + ".asc");
// (file we want to encrypt, file to write encrypted text to, public key)
encryptFile(outputfile.getAbsolutePath(), out, key);
The rest of the example is almost verbatim from the KeyBaseFileProcessor example, I’ll paste the code here, but I didn’t do much to it:
out = new ArmoredOutputStream(out);
ByteArrayOutputStream bOut = new ByteArrayOutputStream();
PGPCompressedDataGenerator comData = new PGPCompressedDataGenerator(PGPCompressedDataGenerator.ZIP);
PGPUtil.writeFileToLiteralData(comData.open(bOut), PGPLiteralData.BINARY, new File(fileName));
comData.close();
PGPEncryptedDataGenerator cPk = new PGPEncryptedDataGenerator(PGPEncryptedDataGenerator.CAST5, new SecureRandom(), "BC");
cPk.addMethod(encKey);
byte[] bytes = bOut.toByteArray();
OutputStream cOut = cPk.open(out, bytes.length);
cOut.write(bytes);
cPk.close();
out.close();
One last thing that I gleamed from their web-based forum was that one of the exceptions thrown by the above code is a PGPException, which itself doesn’t tell you much (in my case it was simply saying exception encrypting session key. PGPException can be a wrapper for an underlying exception though, and you should use the getUnderlyingException() method to determine what the real cause of the problem is (which lead me to the Can't use DSA for encryption message that I mentioned above).
You can download the source code and batch file for the example above here:
Updated 04/07/2004: David Hook wrote to let me know that there is a bug in the examples, I updated both the sample code above and the zip file that contains the full source code. Look at the beta versions for the updated examples.
Scripting in ASP with Java
I’m working on a project right now that involves a store written in Java using Struts and a sister site written in ASP. One of the features of the store requires that the sister site use some logic written in Java, which you might think is impossible. Turns out (doesn’t it always?) that you can quite easily use simple Java methods and objects within ASP from VBScript. I found two articles (and really only 2) that introduced the use of a simple Java class from ASP (which you can read here and here). Here’s a Hello World example:
package org.mycompany;
public class TestClass {
public String sayHello(String name) {
return "Hello " + name;
}
}
compile this and then you save the resulting class file to:
%Win%/Java/TrustLib/%package%/%classname%.class
So the above example would result in a file saved as:
%Win%/Java/TrustLib/org/mycompany/TestClass.class
From ASP, you can then use the following syntax:
Dim obj
set obj = GetObject("java:org.comcompany.TestClass")
result = obj.sayHello("Aaron Johnson");
Response.Write(result)
set obj = nothing
Couple of items of note:
a) the use of what Microsoft calls a “Java Moniker” allows you to use a Java class without first registering it with the system, which is nice (so you got that going for ya),
b) just like a servlet container, if you make changes to the Java class file while the application is running, you must restart the container, which in this case is IIS,
c) you must (as I mentioned before) make sure to place the compiled class file in the appropriately named subdirectory of %Win%/Java/TrustLib/, where %Win% is usually C:\windows\ or C:\winnt\,
d) you can’t use static methods in your Java class if you want to be able to call those methods from VBScript. It appears (from my quick attempts) that the VBScript engine first creates an object using the default constructor and then calls the given method on that instance. Modifiying the method to be static resulted in a runtime error, and finally
e) your code must work in the Microsoft JVM (I think), which isn’t being supported past September 2004.
Using iText PDF & ColdFusion
Mike Steele sent me an email in reference to an article I wrote for the ColdFusion Developer’s Journal a year or so ago. In the email, he mentions that he is trying to use the iText Java-PDF library with ColdFusion MX:
… The getInstance method is static and according to your July 2003 CFDJ article, you can’t instantiate an object in CF this way.
In the article I said this:
… using the CreateObject() function does not get you access to an instance of an object. In order to access a Java object, you must either a) first call the CreateObject() method and then the init() method, which in the above example, maps to the default constructor in Java, or b) call any nonstatic method on the object, which causes ColdFusion to then instantiate the object for you.
I guess this statement needs to be amended to include a third possible, but not always valid solution: call a static method on the class which returns an instance of the object in question. In this case the API designer included a static method ‘getInstance()’ on the PDFWriter class. Given that news, you can take the quick example that the author of the iText library gives here to create a PDF in a snap using ColdFusion:
<cfscript>
// create a 'Document' object
document = CreateObject("java", "com.lowagie.text.Document");
document.init();
// get an outputstream for the PDF Writer
fileIO = CreateObject("java", "java.io.FileOutputStream");
// call the constructor, pass the location where you want
// the pdf to be created
fileIO.init("C:\myhost.com\somedir\test.pdf");
// get a PDF Writer var
writer = CreateObject("java", "com.lowagie.text.pdf.PdfWriter");
// call the static 'getInstance' factory method
writer.getInstance(document, fileIO);
// open the document
document.open();
// create a new paragraph
paragraph = CreateObject("java", "com.lowagie.text.Paragraph");
paragraph.init("Hello World!");
// add the paragraph
document.add(paragraph);
// close the document (PDF Writer is listening and will automatically
// create the PDF for us
document.close();
</cfscript>
Copy that code into a cfml page and make sure you’ve downloaded the iText jar to the /lib/ directory of your ColdFusion server and you should be able to create PDF’s in a jiffy!
Full source code available here.
Cool URIs don’t change…
Tim Berners Lee wrote this essay years ago (1998 in fact), and it’s a good one. In short, the message is this:
… many, many things can change and your URIs can and should stay the same. They only can if you think about how you design them.
Why bring it up now? I got an email from Jens Anders Bakke a couple weeks ago, in it he asked what “… we regular users can do about …” the fact that Macromedia Forums was recently moved (from http://webforums.macromedia.com/ to http://www.macromedia.com/support/forums/). He brought up the fact that alot of people link to the forums when discussing a bug or a problem and because of the move, none of those links that matter (ie: the links that actually point to something besides the forums homepage) work (I’ve done it myself in multiple places). In fact, Google can find about 7,400 links to webforums.macromedia.com. Some of those don’t work anymore. It’s a small thing, but seriously, how hard would it have been to add a couple lines of mod_write kung foo to your Apache conf?