Lots of talk right now about Apple and it’s releasing of Rendezvous (Matt #1, Matt #2, Ted, Marc, Sam) into the wild. I downloaded the Windows Preview and extracted the SDK and was able to get minimally interesting things up and running very easily using Java. Below is a simple class that implements the BrowseListener interface and has utility methods for finding iTunes (protocol = DAAP), HTTP Servers (protocol = HTTP) and printers (protocol = LPR).
// class that implements the BrowseListenr interface
public class TestBrowseListener implements BrowseListener {
DNSSDService myBrowser = null;
public void serviceFound(DNSSDService browser, int flags, int ifIndex,
String serviceName, String regType, String domain) {
// do stuff when a service is found
System.out.println("Service Found\n");
System.out.println("
Category Archives: J2EE
Hibernate DDL Export and SQL Length
Warning! Long story ahead… One of the great features of Hibernate is what it calls “…roundtrip engineering” where you can begin with one artifact (a POJO, a database table, a Hibernate mapping file) and produce all the others from it. You can start with hibernate mapping files (.hbm) that describe your objects and then generate basic POJO’s and your database schema (called DDM in Hibernate) using the Code Generation tools. You can also use Middlegen to generate your Hibernate Mapping Files directly from your database schema. Finally, you can produce mapping files from your compiled Java classes or from Java source with XDoclet markup (using HibernateDocletTask) which you could then use to produce DDM, which is what I spent time doing yesterday using Ant.
This is a new project, so I only had a couple Java classes that needed the Hibernate XDoclet tags added. I noticed yesterday that Cedric Beust had released a JavaDoc Tag Plug-in for Eclipse that ships with a definition file for Hibernate, which made it easy to get started with the Hibernate tags (download it, unzip to the Eclipse ‘plugins’ folder and restart Eclipse). A super simple example class looks like this:
package com.mycompany;
import java.io.Serializable;
/**
* @hibernate.class table="dog"
*/
public class Dog extends BaseBean implements Serializable {
private String name;
private String type;
public Dog() { }
/**
* @hibernate.property name="name" type="string"
* @hibernate.column name="name" length="255" not-null="true"
* @return
*/
public String getName() {
return name;
}
/**
* @hibernate.property name="type" type="string"
* @hibernate.column name="type" length="255" not-null="true"
* @return
*/
public String getType() {
return type;
}
public void setName(String name) {
name = name;
}
public void setType(String type) {
type = type;
}
}
After writing the class, the rest of your work is in Ant, which in turn uses XDoclet and the tools provided by Hibernate. You’ll need to download and extract XDoclet to your system; I added a property to my Ant build file that specifies the location of XDoclet:
<property name="xdoclet.home" value="C:\xdoclet-1.2.1"/>
I read other people who recommended adding XDoclet to the /lib/ directory of your Ant installation. After doing either of the above, you’ll need to define the HibernateDocletTask in Ant:
<taskdef name="hibernatedoclet"
classname="xdoclet.modules.hibernate.HibernateDocletTask">
<classpath refid="xdoclet.classpath"/>
</taskdef>
and then you can use it inside a <target>:
<hibernatedoclet
destdir="WEB-INF/classes"
excludedtags="@version,@author,@todo"
force="true"
mergedir="WEB-INF/classes"
verbose="false">
<fileset dir="src">
<include name="com/mycompany/*.java"/>
</fileset>
<hibernate version="2.0"/>
</hibernatedoclet>
In the above example I have the Hibernate mapping files being generated to /WEB-INF/classes from the Java source filesthat live in the /src/com/mycompany directory. However, this leaves you having to manually update the master Hibernate configuration file (hibernate.cfg.xml) with the references to the generated mapping files. The Hibernate site shows how you can generate the configuration file using BeanShell, but it’s easier than that. The latest version of XDoclet includes a task (HibernateCfgSubTask) that does it for you. Simple add this block of code:
<hibernatecfg
dataSource="java:comp/env/jdbc/pets"
showSql="false"
dialect="net.sf.hibernate.dialect.SQLServerDialect"
destDir="WEB-INF/classes" />
right after the <hibernate version="2.0" /> in the above example. In this example I’m using JNDI to look up a datasource called “pets”, I’m using the SQL Server Hibernate dialect, and I want the task to look in WEB-INF/classes for the Hibernate mapping files.
Wait! We’re not done yet! Because we now have Hibernate mapping files, we can generate a SQL script that will create the appropriate tables in the database. Again, the task needs to be defined:
<taskdef name="schemaexport" classname="net.sf.hibernate.tool.hbm2ddl.SchemaExportTask">
<classpath refid="compile.classpath"/>
</taskdef>
and then we can run the task:
<schemaexport
properties="src/hibernate.properties"
quiet="yes" text="true" drop="false" delimiter=";"
output="WEB-INF/classes/installation.sql">
<fileset dir="WEB-INF/classes" includes="**/*.hbm.xml"/>
</schemaexport>
The task requires that you specify a Hibernate dialect using a properties file (why not add dialect as an attribute like the Hibernatecfg task?) and then can either write the generated SQL to a file or can run the generated SQL against a database.
Anyway, all of this does lead up to a point. One of the puzzling things that I ran into was that I ended up specifying the type of the SQL column in my POJO using the @hibernate.column tag like this:
@hibernate.column name="label" length="255" sql-type="nvarchar"
If you specify a sql-type then the length attribute is not passed through to the generated SQL, which leaves you with SQL that looks like this:
create table dog (
...
name VARCHAR,
type VARCHAR,
...
);
I’m not sure if this is by design or by accident, but Hibernate is open source, so it’s easy to find a work around. The offending code is in the net.sf.hibernate.mapping.Column class and the net.sf.hibernate.mapping.Table class. The Table class is responsible for looping over every column defined in the mapping file and then calls the getSqlType() method on the Column. The Column instance is then responsible for either a) guessing at the SQL type (if type is not defined) or b) returning the defined SQL type. In (a), Hibernate actually does return a length; it guesses that because the property is of type string, that the column should be of SQL type ‘varchar’ and that the length should be 255 characters. But in (b), instead of returning the type and then the length, it only returns type, which in SQL Server means that you’ll end up with all your varchar columns being 1 character in length. The workaround is to either go route (a) and let Hibernate guess what the column type and length should be or (b) you can specify length as part of the type. For instance:
@hibernate.column name="type" sql-type="nvarchar (50)"
which creates a nvarchar column of 50 characters. I know this syntax will work on MySQL as well as SQL Server, I’m not sure about the other database platforms that Hibernate supports. But the bigger question: bug or feature?
Getting IIS 5.x & Tomcat 5.x to play nice
Just for posterity’s sake, directions on how to get IIS 5.1 (ie: Windows XP Professional) and Tomcat 5 to play nicely. The directions assume that you have Tomcat 5.x and IIS 5.x installed and functioning.
a) Download Tomcat Web Server Connector JK 2 (download)
b) extract the isapi_redirector2.dll to the bin directory of your Tomcat installation.
c) add a Virtual Directory in IIS called ‘jakarta’. Point the Local Path to the bin directory of your Tomcat installation (on my system this is: C:\Program Files\Apache Software Foundation\Tomcat 5.0.25\bin\). Give the Virtual Directory Scripts & Executables execute permissions.
d) Create 2 text files in the /conf/ directory of your Tomcat installation called workers2.properties and jk2.properties. Here is a sample workers2.properties:
[channel.socket:localhost:8009]
info=Ajp13 forwarding over socket
tomcatId=localhost:8009
[uri:/samples/*]
info=Map the /samples director
You’ll need to add anything you want mapped from IIS to Tomcat to the [uri:/yoursite] section. Here is a sample jk2 properties file:
# The default port is 8009 but you can use another one
# channelSocket.port=8019
e) Edit your registry: 1) Create a key: HKLM\\SOFTWARE\\Apache Software Foundation\\Jakarta Isapi Redirector\\2.0. 2) Add string values for (no apostrophes) ‘extensionUri’, ‘serverRoot’, ‘workersFile’, ‘authComplete’, and ‘threadPool’. 3) Update the string values for extensionUri to be ‘/jakarta/isapi_redirector2.dll’, serverRoot to be the root of your Tomcat installation (on my system this is ‘C:\Program Files\Apache Software Foundation\Tomcat 5.0.25′), threadPool to be ’20’, and workersFile to be the location of your Tomcat installation + ‘conf\workers2.properties’ (which on my system turns out to be this: ‘C:\Program Files\Apache Software Foundation\Tomcat 5.0.25\conf\workers2.properties’.
f) Restart IIS and Tomcat and you should be golden!
Struts Tips #3
Developing a Java web application (especially in Struts) is different in many ways from developing in ColdFusion, ASP or even ASP.NET. One of the major differences is the structure of the application; generally ColdFusion, ASP and ASP.NET applications are structured around the file system; you end up at http://www.myhost.com/corporate/default.asp or http://www.myhost.com/products/default.cfm. One of the core ideas of Struts is the idea of mapping an action (/cart/checkout/billing) to an Action class (com.myhost.cart.checkout.Billing), the file system doesn’t really come into play. Another variation is the way in which applications are normally deployed (or at least the way I’ve seen them deployed): ASP, ColdFusion and ASP.NET applications are generally deployed at the root of a website while Java web applications introduce the idea of a ‘context’, where the context can be the root (context = “”) or the context can be something else (context = “/store”).
These two differences lead to a major problem if you’re creating web applications with Struts: instead of being able to reference an image using an absolute path like this:
<img src="/images/logo.jpg" />
you need to reference your images using a relative path like this:
<img src="images/logo.jpg" />
But wait! You can’t do that either because the URL of your page could /cart/checkout/billing.do or /products/cars/accessories.do, both of which could be deployed to different servlet context (“/store” for instance). If you used a relative path and then visited a page like /cart/checkout/billing.do, the webserver would request the image from /cart/checkout/images/logo.jpg, which is most likely not where you have it located.
Luckily, the Struts team put together the tag (for images) and the associated tag (for image buttons). The tags are pretty easy to pick and use. Putting an image on a page is going to take the form of:
<html:img src="/images/logo.jpg" />
or
<html:img page="/images/logo.jpg" />
The first one won’t help much in the context of this discussion; it has the exact same problems as using a regular old <img src="..." /> tag, except that the URL will be rewritten for users that don’t accept cookies. The second option is much more useful. If you use the page attribute instead of the src attribute, the “…image will automatically prepend the context path of this web application (in the same manner as the page attribute on the link tag works), in addition to any necessary URL rewriting. (src)”
Using the <html:image /> tag is really no different, so I won’t get into it (it generates an <input type="image" ... /> tag), other than to mention that it doesn’t accept height or width attributes and it doesn’t (like all JSP tag attributes) pass them through to the generated tag, which could cause problems if you migrate all your <input type="image" .../> tags over to <html:image />.
In short, if you’re developing a Struts application, make sure to familiarize yourself with all the tags, doing so can save you alot of time when your boss decides that the application should be deployed in a different servlet context.
More:
- Jakarta Struts Documentation: Struts HTML tags
- Struts Tips: Use rewrite to reference HTML assets
- Web Diner: Understanding Paths, URLs and Links
Scheduled Tasks using Quartz
Where I work we run about 30-40 public web sites deployed across a variety of servers in development, staging and live environments. One of my personal goals is to automate the deployment process, making it as close to foolproof as possible (no touching!) to deploy an application to any (or all) of the environments. To that end, I’d really like to get rid of are the scheduled tasks we have implemented using Microsoft Windows Task Scheduler (which requires touching). Almost every application we write has at least one process that needs to be fired every couple minutes or every night at 5:30am. With ASP, this means that we have to write a script in VBScript that is called by WGET which is called by WSH which is then called by a Windows Scheduled Task. Lucky for me, I’m working with Java on my current project.
I found Quartz when I was exploring the Scheduled Details option under ‘Administration –> System’ in our Jira installation. Quartz is described as an: “ open source job scheduling system that can be integrated with, or used along side virtually any J2EE or J2SE application“; in short it provides close to the same functionality as Windows Task Scheduler or cron but it can be embedded within your application, which means a zero touch deployment. An added benefit is that the scheduled tasks are now running in the same JVM as the application to which it was deployed, whereas a job scheduled and executed using a Windows .bat file and the Windows Task Scheduler runs in a separate JVM. Additionally, it can be configured using a text file rather than a GUI and the jobs and triggers can optionally be persisted to a database.
Using Quartz is a piece of cake. After adding the quartz.jar (download) to my classpath, the jobs that I had written previously to be run from the command line were modified to implement the Job interface, which requires only that the class have an execute(JobExecutionContext context) method that returns void. To schedule and run the jobs is a bit more complicated. Because I didn’t want to persist the jobs or job schedules to a database and I wanted the jobs to run in the context of a web application, I needed a way to schedule the jobs when the application was started. In a web application you can do this by creating a listener (technically a ServletContextListener) that takes action when the contextInitialized(ServletContextEvent context) event is fired. Inside that method, you’d then start the scheduler, create your jobs and triggers and then schedule the jobs:
// create & start the scheduler
SchedulerFactory factory = new StdSchedulerFactory();
Scheduler scheduler = factory.getScheduler();
scheduler.start();
// create the job & trigger
JobDetail job = new JobDetail("myjob",
Scheduler.DEFAULT_GROUP, JobClass.class);
CronTrigger trigger = new CronTrigger("inventory",
Scheduler.DEFAULT_GROUP, "0 15 4 * * ?");
// schedule the job
scheduler.scheduleJob(job, trigger);
Make sure that the listener is added to your web.xml deployment descriptor:
<listener>
<listener-class>com.mycompany.tasks.SchedulerLauncher</listener-class>
</listener>
and you’re all set.
If it sounds interesting, definitely check out the documentation and the tutorial.
why create jSearch?
One of the comments posted to the blog entry introducing jSearch asked why I thought it needed to be created when a tool like nutch already exists. nutch is a massive undertaking, it’s aim is to create a spider and search engine capable of spidering, indexing and searching billions of web pages while also providing a close shave and making breakfast. nutch wants to be an open source version of google. I created jSearch to be a smaller version of google, indexing single websites or even subsections of a website; more like a departmental or corporate spider, indexing and searching system. If you download the application, you’ll see that jSearch provides some of the same functionality that google does: cached copies of web pages, an XML API (using REST intead of SOAP), logging and reporting of searches and content summarization. Sure, you could use the google web api to provide the same search on your own site, but then you’re limited to the number of searches that google allows per day (1000) with the API, you’re making calls over your WAN to retrieve search results and you have less control (ie: you couldn’t have google index your intranet unless you purchased their appliance).
The second reason I created jSearch was that it was and is an interesting problem to work on. I now have a unique appreciation for the problems that google (or any other company that has created a spider and search engine) has faced. Writing a spider is not a trivial task. Creating a 2 or 3 sentence summary of an HTML page (technically called ‘Text Summarization’) is a topic for master’s thesis. And putting a project like this together becomes a study of the various frameworks for search (Lucene), persistence (Hibernate), and web application development (Struts), which is software engineering.
And really, why not? I enjoyed it. It was interesting and I learned something along the way and I plan on using it.
introducing jSearch
I’ve been scratching an itch off and on for a couple months now on a project I finally called jSearch (naming suggestions are welcomed!). jSearch is a tool for spidering (give it a host name and optionally a path and it will attempt to find every HTML page on that site), indexing (the content of the site is stripped of HTML and then indexed using Lucene), archiving (a copy of every page is saved to a database so that you can provide ‘cached’ copies of pages just like Google) and searching (either via a secure web-based form, a non-secure XML API or optionally by copying the Lucene indexes) websites using Java technology.
jSearch is built on a variety of open source software including Struts 1.1, Lucene 1.3, the Jakarta Commons project, Hibernate, log4J, MySQL (although it should work with every database that Hibernate supports), dom4j, Classifier4J, JFreeChart and the cewolf JSP graphing tags. The web crawling technology was inspired by work done in the Jakarta LARM project, which is a subproject of Lucene.
If you have a chance, you download the war file here, deploy it to Tomcat (or your favorite servlet container), and then make a couple modifications:
a) decide which database you’re going to use; the war file includes the MySQL driver
b) download and add the appropriate database driver jar files to the /WEB-INF/lib directory
c) create the database using the mysql_createtables.sql file (or use the SchemaExport hbm2ddl tool included with Hibernate to create an install for your flavor of persistence)
d) modify the hibernate.cfg.xml: update it with the appropriate driver class, the database connection URL, username, password and database dialect
e) manually add your email address and password to the ‘jsearch_user’ table:
INSERT INTO jsearch_user (label,fname,lname,emailaddr,password,type,active)
VALUES('Aaron Johnson','Aaron','Johnson','aaron.s.johnson@gmail.com','password','ADMIN',1)
e) restart Tomcat…
After restarting Tomcat you should be able to access jSearch by going to http://{yourhost}/jsearch/. You’ll see the login screen; enter your username and password (the one that you created in step e) and then click the ‘login’ button.
Your first step will be to create an ‘index’ which is a combination of a ‘host’ (ie: www.yahoo.com), a ‘path’ (ie: /sports/), an index path (the place where you want the Lucene indexes maintained), and check the box to activate reporting (which means that jSearch will keep a record of every search performed against the system).
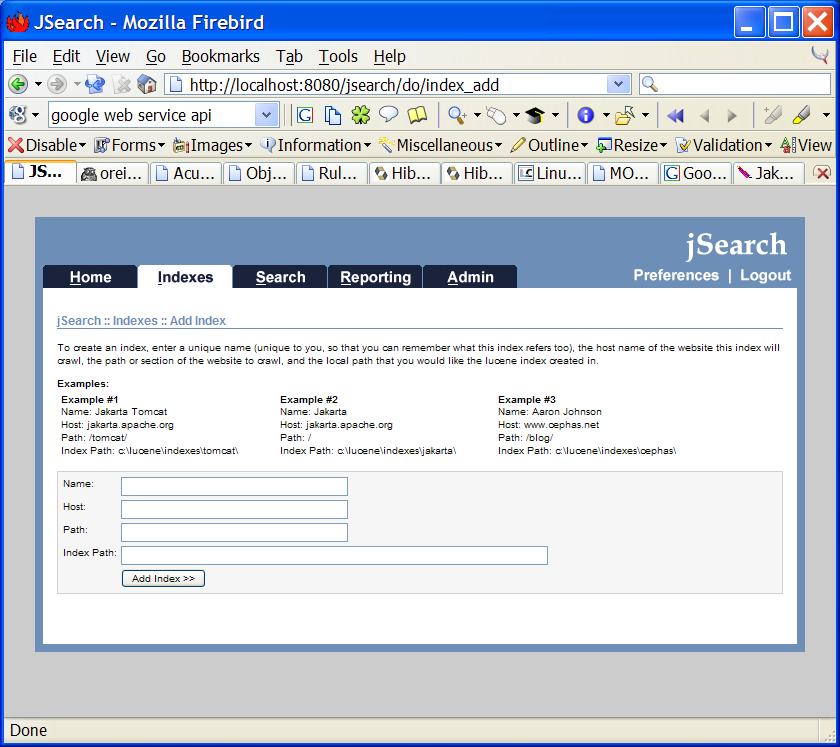
After saving the index, you’ll need to have jSearch start the spidering process. Check the box next to the index (or indexes) you created and then click the ‘spider selected indexes’ link in the lower right hand corner. jSearch will kick off multiple processes within the context of the servlet container (jSearch can also be run from the command line if necessary) and will begin to download, parse, index and archive all the pages within the host/path combination.

When the spidering process has been completed, you can use the ‘search’ tab to search an index using Lucene’s query parser syntax. After completing a search, you should see a link at the bottom of the page for the ‘xml/rest view’, which is similar in function to the Google Web APIs, except that is uses REST instead of SOAP. The jSearch Web APIs can be programatically used by other web or desktop applications.
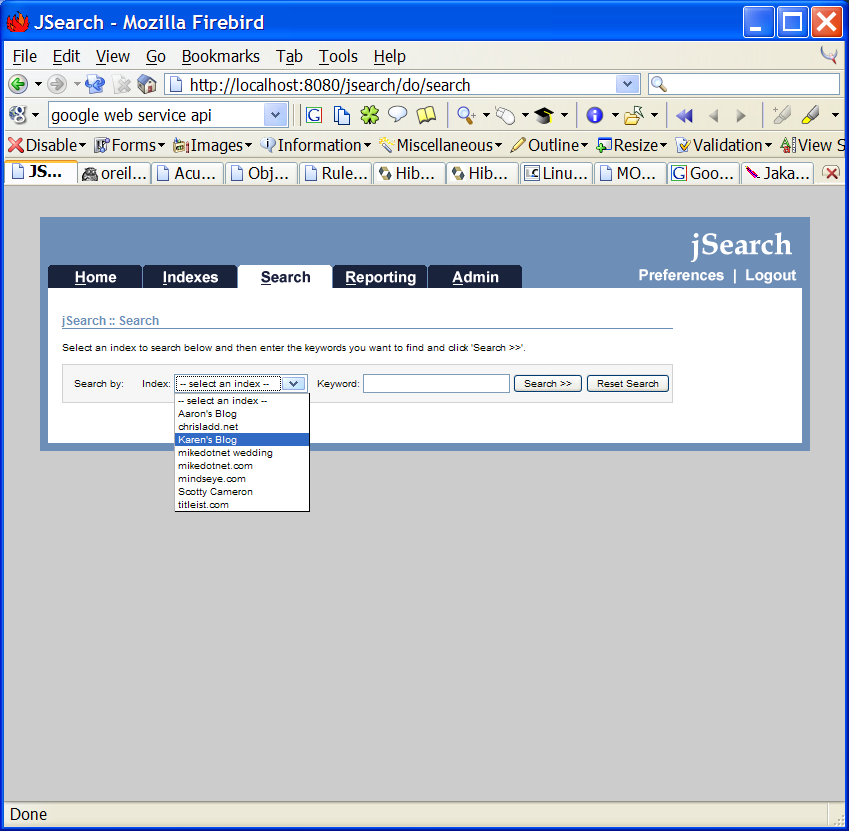
Next, you can use the ‘reporting’ tab to view keyword search reports to see how many searches the system is handling per day, per week, per month and also to see what the top keywords being searched are.
Finally, you can create / edit / delete users that are allowed to login to the system using the ‘admin’ tab.
I’d love to get any feedback you have about the application if you use it; comment on this post or send me an email.
Hibernate: Using ‘native’ identifier generation
The nice folks at Apress sent me a couple books (Enterprise Java Development on a Budget: Leveraging Java Open Source Technologies, Pro Jakarta Struts and Beginning J2EE 1.4: From Novice to Professional) to review. Last night I was glancing through the object relational mapping chapter of the Enterprise Java Development on a Budget book and read about mapping identity columns using Hibernate. The sites I work on are mostly SQL Server and MySQL, so I’ve been using the ‘identity’ generator, which “… supports identity columns in DB2, MySQL, MS SQL Server, Sybase and HypersonicSQL.” (in contrast to the sequence generator which uses a sequence in DB2, PostgreSQL, Oracle, SAP DB, McKoi or a generator in Interbase) The book mentioned that the ‘native’ generator “… intelligently chooses the appropriate strategy” from among the identity, sequence or hilo generators. Hibernate never ceases to amaze.
JSTL XML tag problem: Cannot inherit from final class
I’m trying to use the JSTL XML tags in a JSP page and I’m getting this error:
java.lang.VerifyError: Cannot inherit from final class
java.lang.ClassLoader.defineClass0(Native Method)
java.lang.ClassLoader.defineClass(ClassLoader.java:502)
java.security.SecureClassLoader.defineClass(SecureClassLoader.java:123)
...WebappClassLoader.findClassInternal(WebappClassLoader.java:1634)
...WebappClassLoader.findClass(WebappClassLoader.java:860)
...WebappClassLoader.loadClass(WebappClassLoader.java:1307)
...WebappClassLoader.loadClass(WebappClassLoader.java:1189)
java.lang.ClassLoader.loadClassInternal(ClassLoader.java:315)
org.apache.taglibs.standard.tag.common.xml.ForEachTag.prepare(ForEachTag.java:88)
javax.servlet.jsp.jstl.core.LoopTagSupport.doStartTag(LoopTagSupport.java:262)
org.apache.jsp.test_jsp._jspx_meth_x_forEach_0(test_jsp.java:176)
org.apache.jsp.test_jsp._jspService(test_jsp.java:84)
org.apache.jasper.runtime.HttpJspBase.service(HttpJspBase.java:94)
javax.servlet.http.HttpServlet.service(HttpServlet.java:810)
org.apache.jasper.servlet.JspServletWrapper.service(JspServletWrapper.java:298)
org.apache.jasper.servlet.JspServlet.serviceJspFile(JspServlet.java:292)
org.apache.jasper.servlet.JspServlet.service(JspServlet.java:236)
javax.servlet.http.HttpServlet.service(HttpServlet.java:810)
when trying to execute this code:
<c:set var="xmlText">
<a>
<b>
<c>
foo
</c>
</b>
<d>
bar
</d>
</a>
</c:set>
<x:parse var="a" doc="${xmlText}" />
<x:out select="$a//c"/>
which is straight out of the JSTL examples application in the Java Web Services Tutorial v1.3. I’m running the latest version of Tomcat (version 5.0.25) on Windows XP if that matters.
Can anyone help?
Update: 06/03/2004: Thanks Kris! Adding xalan.jar to the {tomcat}/common/endorsed/ path fixed the problem.
Hibernate: Deleting Objects
It might look like this is turning into a Hibernate blog… maybe it’s just a phase I’m going through. This last week I ran into a place in some code where I wanted to write a query to delete a number of rows from the database. Deleting a single row using Hibernate is simple; get an instance of the persistent object you want to delete (ie: a Book, etc..) and an instance of the Session object and then called the delete(Object) method:
long bookid = 12;
Session sess = HibernateFactory.currentSession();
Object book = sess.load(Book.class, bookid);
sess.delete(book);
Easy. Now, if you wanted to delete all the computer books for some reason, you’d have to first query the database using Hibernate to get a Collection of books, then iterate over the books, calling delete(Object object) on each one.
Collection books = BookFactory.getComputerBooks();
Session sess = HibernateFactory.currentSession();
for (Iterator i = books.iterator(); i.hasNext();) {
Book book = (Book)i.next();
sess.delete(book);
}
It’s easier than that though. The Session object has a delete(String query) method that I originally thought took a standard SQL ‘delete from table where…’ statement. After fussing with it for a bit, I read the documentation which says: “Delete all objects returned by the query. Return the number of objects deleted.”. Aha! Instead of calling delete() on each one, you use a SQL (or a HQL) statement that fetches the objects and then pass the results directly to the delete method:
Session sess = HibernateFactory.currentSession();
sess.delete("select book FROM org.mycompany.Book as book where type = 'technical'");
Just another example of how Hibernate makes it easier to work with relational databases.