I’ve been scratching an itch off and on for a couple months now on a project I finally called jSearch (naming suggestions are welcomed!). jSearch is a tool for spidering (give it a host name and optionally a path and it will attempt to find every HTML page on that site), indexing (the content of the site is stripped of HTML and then indexed using Lucene), archiving (a copy of every page is saved to a database so that you can provide ‘cached’ copies of pages just like Google) and searching (either via a secure web-based form, a non-secure XML API or optionally by copying the Lucene indexes) websites using Java technology.
jSearch is built on a variety of open source software including Struts 1.1, Lucene 1.3, the Jakarta Commons project, Hibernate, log4J, MySQL (although it should work with every database that Hibernate supports), dom4j, Classifier4J, JFreeChart and the cewolf JSP graphing tags. The web crawling technology was inspired by work done in the Jakarta LARM project, which is a subproject of Lucene.
If you have a chance, you download the war file here, deploy it to Tomcat (or your favorite servlet container), and then make a couple modifications:
a) decide which database you’re going to use; the war file includes the MySQL driver
b) download and add the appropriate database driver jar files to the /WEB-INF/lib directory
c) create the database using the mysql_createtables.sql file (or use the SchemaExport hbm2ddl tool included with Hibernate to create an install for your flavor of persistence)
d) modify the hibernate.cfg.xml: update it with the appropriate driver class, the database connection URL, username, password and database dialect
e) manually add your email address and password to the ‘jsearch_user’ table:
INSERT INTO jsearch_user (label,fname,lname,emailaddr,password,type,active)
VALUES('Aaron Johnson','Aaron','Johnson','aaron.s.johnson@gmail.com','password','ADMIN',1)
e) restart Tomcat…
After restarting Tomcat you should be able to access jSearch by going to http://{yourhost}/jsearch/. You’ll see the login screen; enter your username and password (the one that you created in step e) and then click the ‘login’ button.
Your first step will be to create an ‘index’ which is a combination of a ‘host’ (ie: www.yahoo.com), a ‘path’ (ie: /sports/), an index path (the place where you want the Lucene indexes maintained), and check the box to activate reporting (which means that jSearch will keep a record of every search performed against the system).
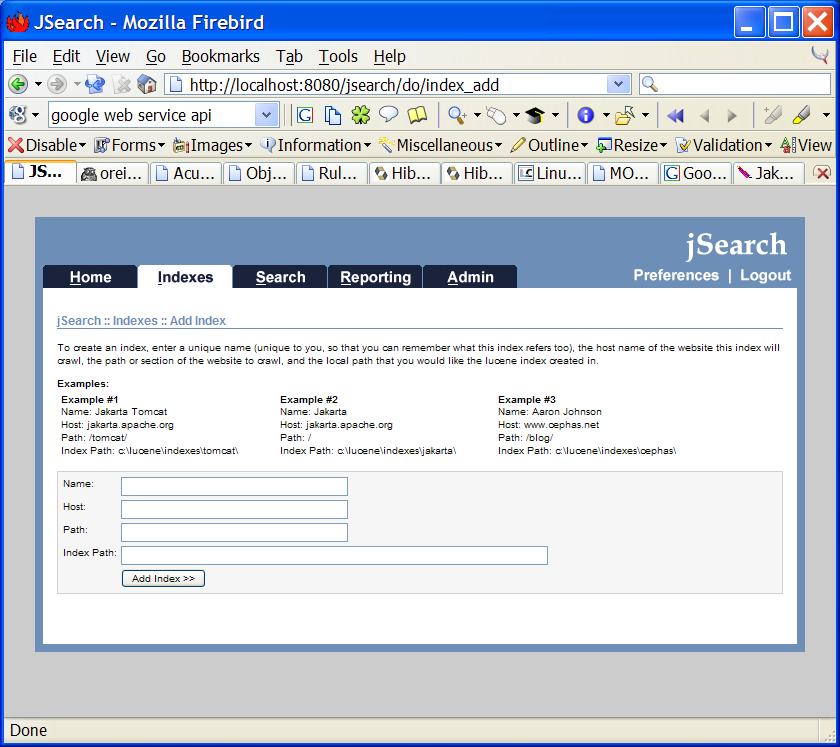
After saving the index, you’ll need to have jSearch start the spidering process. Check the box next to the index (or indexes) you created and then click the ‘spider selected indexes’ link in the lower right hand corner. jSearch will kick off multiple processes within the context of the servlet container (jSearch can also be run from the command line if necessary) and will begin to download, parse, index and archive all the pages within the host/path combination.

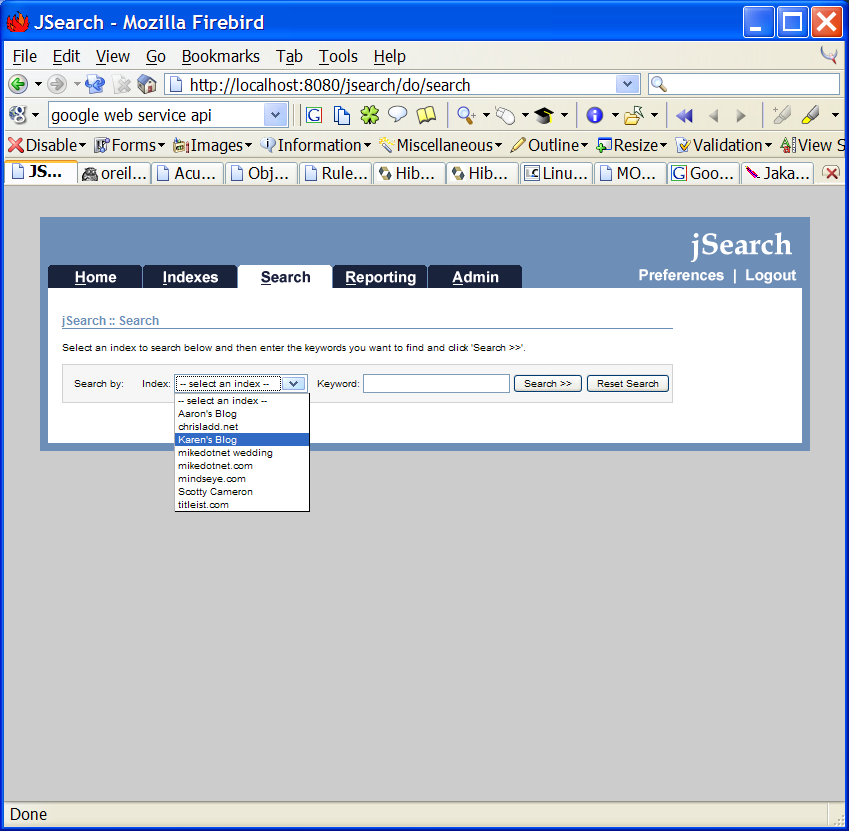
When the spidering process has been completed, you can use the ‘search’ tab to search an index using Lucene’s query parser syntax. After completing a search, you should see a link at the bottom of the page for the ‘xml/rest view’, which is similar in function to the Google Web APIs, except that is uses REST instead of SOAP. The jSearch Web APIs can be programatically used by other web or desktop applications.
Next, you can use the ‘reporting’ tab to view keyword search reports to see how many searches the system is handling per day, per week, per month and also to see what the top keywords being searched are.
Finally, you can create / edit / delete users that are allowed to login to the system using the ‘admin’ tab.
I’d love to get any feedback you have about the application if you use it; comment on this post or send me an email.
How does JSearch differ from Nutch (www.nutch.org)
From the description of jSearch, it is not designed (purposely) for the same domain as Nutch. Nutch is a full, very scalable, distributed crawling, indexing and search solution made to handle very large, multi-billion web page indices. jSearch seems to restrict its operation to a single web server, so it is more suitable for intra-company use or some such.
I have set up the application as mentioned above but when I try to log on using the emailaddress and password, it always return with a message the username and password do not match. Is there anything that I am missing?
hi Qasim,
Did you run the sample SQL insert script that I mentioned in the install (ie: INSERT INTO …)? If not, you’ll never been able to login. You might also try updating the log4j.properties file in /WEB-INF/classes/ and then tail that to see if the application is spitting out any useful information (which you could then send to me).
AJ
Sweet!! Nice job!
There’s a typo in that INSERT statement. jsearch_user table has column “emailaddr” but INSERT statement uses “emailaddress”. Other than that everything worked fine.
I installed jsearch following your steps in this post.
When i logon to jsearch the home page is shown, but when i click on the link for any other page it shows the login page again and it doesnt help to login again it does the same.
Any clues ?
BTW what you using Classifier4J for in your spider?
Thanks Justin
hey Justin,
If you use the web-based search (or the REST XML interface to search) within jSearch, you’ll see that that search results contain a summary of the HTML document (or at least an attempt at a summary… it’s not easy). I use classifier4j to create the summary, specifically the SimpleSummariser class (http://classifier4j.sourceforge.net/apidocs/net/sf/classifier4J/summariser/SimpleSummariser.html).
I would be interested in helping you add PDF indexing support. I have also figured how to index .doc file. I am working on ppt files as well.
I’va already tried it and honestly jSearch is awesome! AJ, I wonder how much spare time you need to accomplish all your fantastic projects…
Thats a great project! However I could not run it properly using postgres database. I have changed the id generator, because postres uses sequences and my log accuses: ERROR org.jsearch.dao.HibernateFactory – could not instantiate id generator. In addition, in the screen, I have the following message: ” java.lang.NoClassDefFoundError, org.jsearch.dao.UserDAO.getUser ” that I do not belive that is the cause of the problem since I have the UserDAO class file. If anybody could help me, I thanks in advance.
The Kuali Foundation fosters the development of open source enterprise applications for higher education. Some of it’s applications include financial/accounting, grant management, human resources, student information, etc. Some of these applications are considering the use of your jsearch work as mentioned on http://cephas.net/blog/2004/06/09/introducing-jsearch/.
I have been trying to track down licensing terms for the use of this software. Before any Kuali product can consider the use of such software, we need to understand how it is licensed. I had a look inside the WAR, but didn’t find any licensing information there. Please provide a pointer or link to the licensing terms for use of this software.
Hi AJ,
The war file is not working with Tomcat 7.0 with Mysql5.0 i have changed the hibernate configuration.
INFO: Deploying web application archive C:\Tomcat\webapps\jsearch.war
Jun 17, 2012 5:48:20 PM org.apache.tomcat.util.digester.Digester startElement
SEVERE: Begin event threw exception
java.lang.IllegalArgumentException: taglib definition not consistent with specification version
at org.apache.catalina.startup.TaglibLocationRule.begin(WebRuleSet.java:1240)
at org.apache.tomcat.util.digester.Digester.startElement(Digester.java:1276)
at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.startElement(AbstractSAXParser.java:501)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanStartElement(XMLDocumentFragmentScannerImpl.java:1363)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(XMLDocumentFragmentScannerImpl.java:2755)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(XMLDocumentScannerImpl.java:648)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(XMLDocumentFragmentScannerImpl.java:511)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:808)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:737)
at com.sun.org.apache.xerces.internal.parsers.XMLParser.parse(XMLParser.java:119)
at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.parse(AbstractSAXParser.java:1205)
at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:522)
at org.apache.tomcat.util.digester.Digester.parse(Digester.java:1537)
at org.apache.catalina.startup.ContextConfig.parseWebXml(ContextConfig.java:1825)
at org.apache.catalina.startup.ContextConfig.webConfig(ContextConfig.java:1201)
at org.apache.catalina.startup.ContextConfig.configureStart(ContextConfig.java:855)
at org.apache.catalina.startup.ContextConfig.lifecycleEvent(ContextConfig.java:345)
at org.apache.catalina.util.LifecycleSupport.fireLifecycleEvent(LifecycleSupport.java:119)
at org.apache.catalina.util.LifecycleBase.fireLifecycleEvent(LifecycleBase.java:90)
at org.apache.catalina.core.StandardContext.startInternal(StandardContext.java:5161)
at org.apache.catalina.util.LifecycleBase.start(LifecycleBase.java:150)
at org.apache.catalina.core.ContainerBase.addChildInternal(ContainerBase.java:895)
at org.apache.catalina.core.ContainerBase.addChild(ContainerBase.java:871)
at org.apache.catalina.core.StandardHost.addChild(StandardHost.java:615)
at org.apache.catalina.startup.HostConfig.deployWAR(HostConfig.java:962)
at org.apache.catalina.startup.HostConfig$DeployWar.run(HostConfig.java:1603)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:441)
at java.util.concurrent.FutureTask$Sync.innerRun(FutureTask.java:303)
at java.util.concurrent.FutureTask.run(FutureTask.java:138)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:662)
Jun 17, 2012 5:48:20 PM org.apache.catalina.startup.ContextConfig parseWebXml
SEVERE: Parse error in application web.xml file at jndi:/localhost/jsearch/WEB-INF/web.xml
java.lang.IllegalArgumentException: taglib definition not consistent with specification version
at org.apache.tomcat.util.digester.Digester.createSAXException(Digester.java:2687)
at org.apache.tomcat.util.digester.Digester.createSAXException(Digester.java:2719)
at org.apache.tomcat.util.digester.Digester.startElement(Digester.java:1279)
at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.startElement(AbstractSAXParser.java:501)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanStartElement(XMLDocumentFragmentScannerImpl.java:1363)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(XMLDocumentFragmentScannerImpl.java:2755)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(XMLDocumentScannerImpl.java:648)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(XMLDocumentFragmentScannerImpl.java:511)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:808)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:737)
at com.sun.org.apache.xerces.internal.parsers.XMLParser.parse(XMLParser.java:119)
at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.parse(AbstractSAXParser.java:1205)
at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:522)
at org.apache.tomcat.util.digester.Digester.parse(Digester.java:1537)
at org.apache.catalina.startup.ContextConfig.parseWebXml(ContextConfig.java:1825)
at org.apache.catalina.startup.ContextConfig.webConfig(ContextConfig.java:1201)
at org.apache.catalina.startup.ContextConfig.configureStart(ContextConfig.java:855)
at org.apache.catalina.startup.ContextConfig.lifecycleEvent(ContextConfig.java:345)
at org.apache.catalina.util.LifecycleSupport.fireLifecycleEvent(LifecycleSupport.java:119)
at org.apache.catalina.util.LifecycleBase.fireLifecycleEvent(LifecycleBase.java:90)
at org.apache.catalina.core.StandardContext.startInternal(StandardContext.java:5161)
at org.apache.catalina.util.LifecycleBase.start(LifecycleBase.java:150)
at org.apache.catalina.core.ContainerBase.addChildInternal(ContainerBase.java:895)
at org.apache.catalina.core.ContainerBase.addChild(ContainerBase.java:871)
at org.apache.catalina.core.StandardHost.addChild(StandardHost.java:615)
at org.apache.catalina.startup.HostConfig.deployWAR(HostConfig.java:962)
at org.apache.catalina.startup.HostConfig$DeployWar.run(HostConfig.java:1603)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:441)
at java.util.concurrent.FutureTask$Sync.innerRun(FutureTask.java:303)
at java.util.concurrent.FutureTask.run(FutureTask.java:138)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:662)
Caused by: java.lang.IllegalArgumentException: taglib definition not consistent with specification version
at org.apache.catalina.startup.TaglibLocationRule.begin(WebRuleSet.java:1240)
at org.apache.tomcat.util.digester.Digester.startElement(Digester.java:1276)
… 30 more
Jun 17, 2012 5:48:20 PM org.apache.catalina.startup.ContextConfig parseWebXml
SEVERE: Occurred at line 83 column 11
Jun 17, 2012 5:48:20 PM org.apache.catalina.startup.ContextConfig configureStart
SEVERE: Marking this application unavailable due to previous error(s)
looks like version conflict, please suggest for Tomcat 7.0.27.
Regards,
Ronald
here are the changes i made,
com.mysql.jdbc.Driver
jdbc:mysql://localhost/jsearch
root
false
net.sf.hibernate.dialect.MySQLDialect